Specialized eCommerce AI
brainpowa’s large language models are purpose-built for eCommerce, delivering empathetic, multi-turn conversations and precise product recommendations with near-zero hallucinations. Unlike generalist models like Llama 4, Mistral Large, or GPT-4.1, our models are fine-tuned for vertical-specific tasks (fashion, electronics, groceries, multi-vertical ), emphasising:
- Empathetic Engagement: Emotionally intelligent responses to foster trust and drive conversions.
- Contextual Relevance: Grounded recommendations tailored to user needs and merchant inventory.
- Transactional Efficiency: Streamlined purchase paths with low-latency responses for real-time support.
- Scalable Customisation: Fine-tuning on private datasets for merchant-specific solutions, aligning with our Model-as-a-Service vision.
Our models eliminate the bloat of large-scale LLMs, running efficiently on GPUs while matching or surpassing public giants in eCommerce performance.
brainpowa’s suite is optimized for eCommerce excellence
Models Highlights:
- brainpowa-empathetic-128K: Lightweight, emotionally intelligent; leads in empathetic sales and supportive language for customer retention.
- brainpowa-contextual-128K: Prioritizes relevance and hallucination avoidance; delivers personalized recommendations.
- brainpowa-salesclosing-128K: Sales-focused; shines in transactional efficiency and empathetic sales closing, with promising checkout success.
- brainpowa-multi-gpu-14B: Balances efficiency and performance; strong in domain knowledge and follow-up appropriateness.
- brainpowa-single-gpu-27B: Flagship for dynamic interactions; excels in conversational engagement, answer relevancy, and multi-turn coherence. Ideal for attribute extraction and upselling with large context.
- brainpowa-comparison-1-5B: Fine-tuned LLM Agent for comparing products or options with concise reasoning.
- brainpowa-problem-based-128K: Understands vague problem statements, asks clarifying questions, and provides empathetic, solution-oriented responses.
Grounded in merchant product data, our models ensure precise, hallucination-free responses, supporting fine-tuning for vertical-specific needs.
Evaluation Framework: Customized for eCommerce Realities
brainpowa’s metrics are laser-focused on customer outcomes, not abstract benchmarks. We evaluated across:
- Single-Turn Benchmarks: Evaluated on diverse eCommerce queries, including empathetic and product-focused scenarios, ensuring relevance and clarity in customer interactions.
- Multi-Turn Conversations: Tested through dynamic dialogues mimicking real-world eCommerce purchase journeys, assessing sustained engagement and contextual continuity.
- Specialized Assessments: Focused on transactional efficiency, empathetic sales, and safety (bias/toxicity), tailored to eCommerce priorities for seamless conversions and trust.
- Arena Comparisons: Conducted extensive head-to-head evaluations of response generated from our models against public models using an LLM judge, measuring relevance, empathy, helpfulness, friendly, and humanlike.
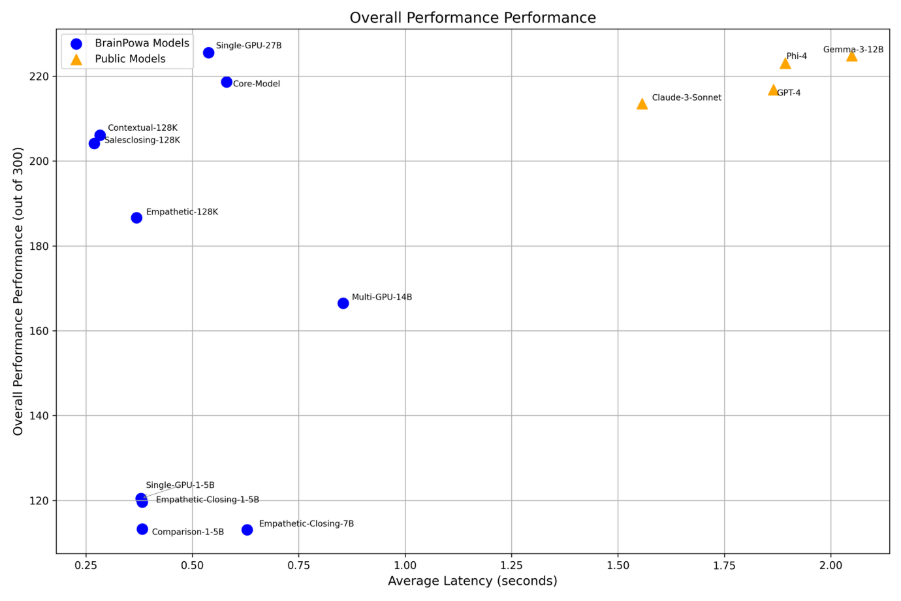
Overall Evaluated Performance are compared against the public model
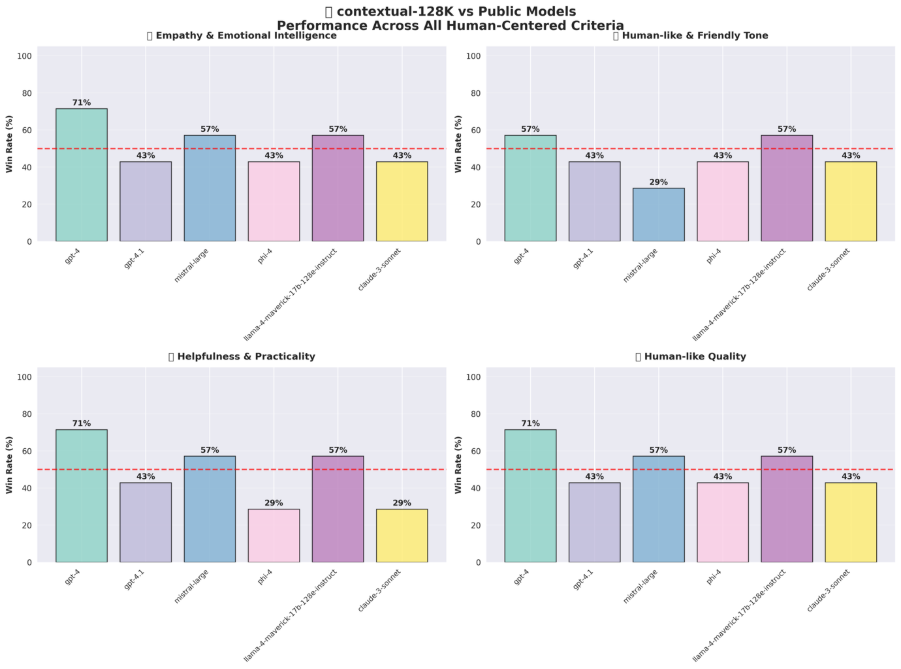
Highlights from the Arena Comparisons:
brainpowa models dominated in head-to-head evaluations against GPT-4, GPT-4.1, Mistral Large, Phi-4, Llama-4-Maverick, and Claude-3-Sonnet, showcasing superior empathy, contextual relevance, and low-latency performance in eCommerce scenarios:
- Contextual-128K: Attained a 52.4% win rate (7.8/10 avg score), with strong empathy (up to 71.4%) and relevance (up to 71.4%), beating GPT-4 (7.5/10) in complex query handling.
- Empathetic-128K: Secured a 100% win rate (8.8/10 avg score), excelling in empathy (100%) and friendliness (100%), surpassing Mistral Large (7.0/10) and Phi-4 (7.2/10) for retention-focused interactions.
- Multi-GPU-14B: Earned a 45.2% win rate (7.2/10 avg score), delivering robust empathy (up to 71.4%) and helpfulness (up to 71.4%), outperforming Llama-4-Maverick (7.0/10).
- Single-GPU-27B: Achieved a 100% win rate (8.9/10 avg score), with perfect empathy (100%), relevance/coherence (100%), and high helpfulness (up to 85.7%), outperforming GPT-4 (7.4/10) and Claude-3-Sonnet (7.5/10).
Smaller Size, Bigger Impact:
Empathetic Model achieved 100% win rate (8.8/10), unmatched empathy (100%) and friendliness, ideal for retention. Which is a very smaller model in comparison with the compared giant models.
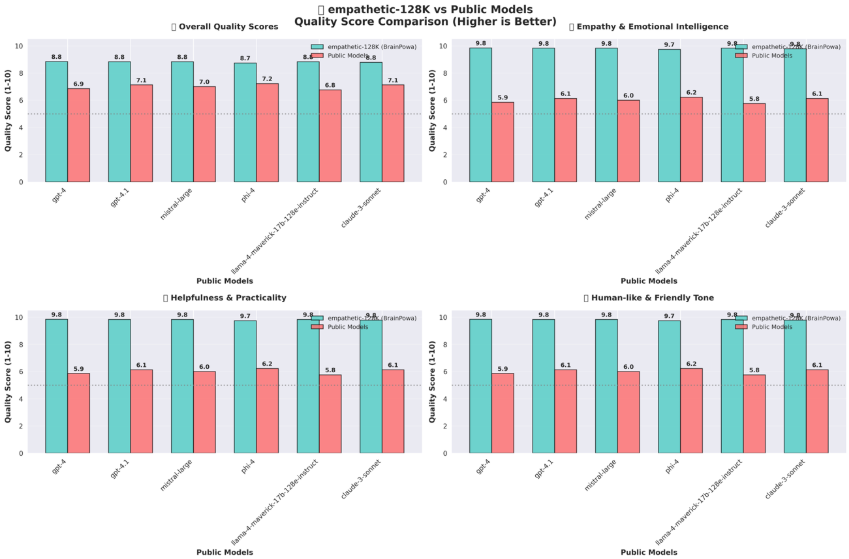
Similarly edge to edge performance of Contextual Model against the Public giant models are below: